

人工智能的新技能不是提示,而是上下文工程

开源小兵
“上下文工程”是一个在人工智能领域日益流行的新术语。人们的讨论正从“提示词工程”转向一个更广泛、更强大的概念: 上下文工程 。tobi lutke 将其描述为“为 LLM 提供所有可合理解决的任务上下文的艺术”。他是正确的。
随着智能体的兴起,将哪些信息加载到“有限的工作记忆”中变得越来越重要。我们发现,决定智能体成败的关键在于你赋予它的上下文的质量。大多数智能体失败不再是模型失败,而是上下文失败。
上下文是什么?
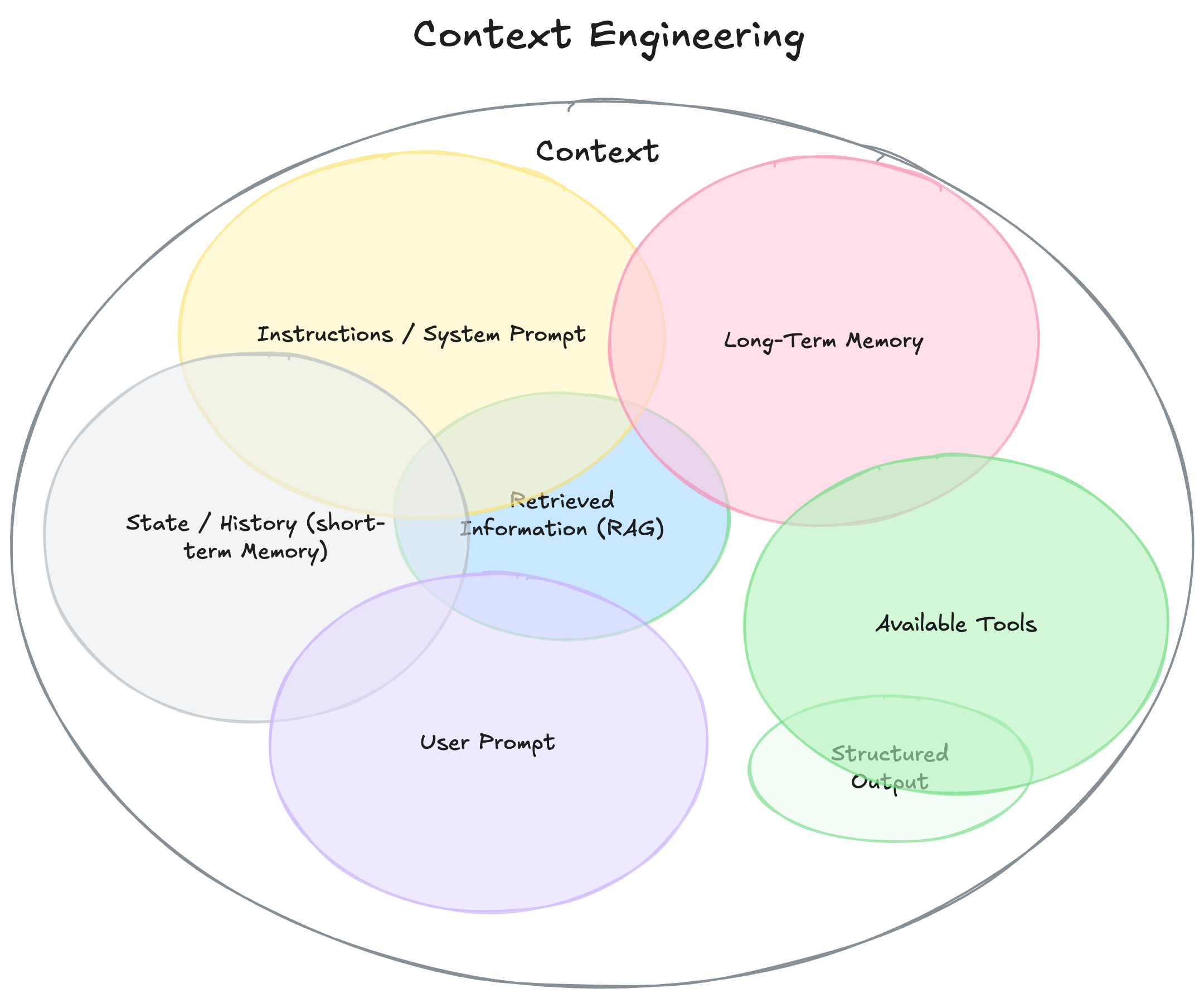
要理解上下文工程,我们必须首先扩展“上下文”的定义。它不仅仅是你发给 LLM 的那一个问题。你可以把它想象成模型在生成答案之前所看到的一切。
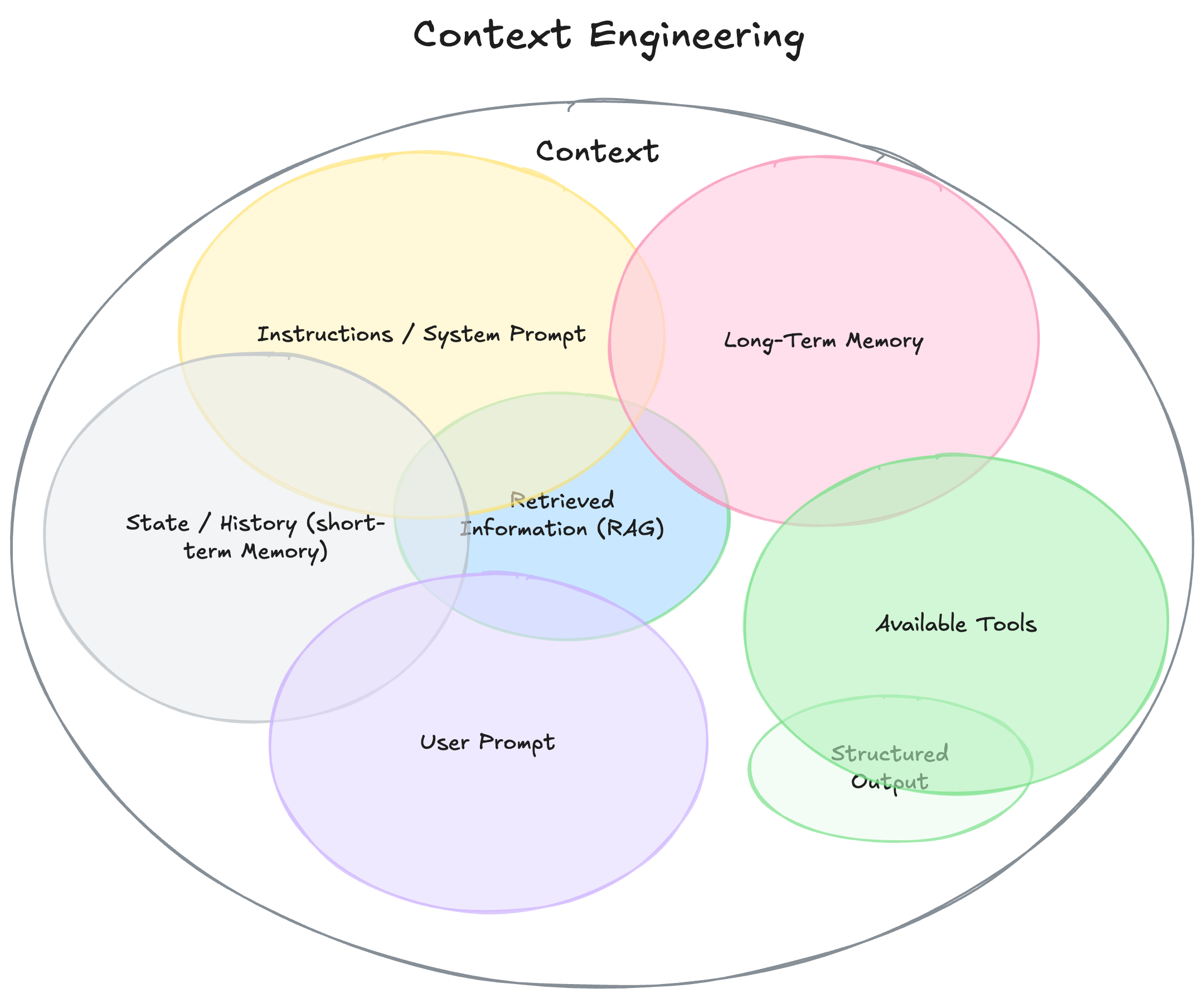
- 说明/系统提示: 定义模型在对话过程中的行为的初始说明集,可以/应该包括示例、规则……
- 用户提示: 来自用户的即时任务或问题。
- 状态/历史(短期记忆): 当前对话,包括导致这一时刻的用户和模型响应。
- 长期记忆: 持久的知识库,通过多次先前的对话收集而来,包含学习到的用户偏好、过去项目的总结或被告知要记住以备将来使用的事实。
- 检索信息 (RAG): 外部的、最新的知识,来自文档、数据库或 API 的相关信息,用于回答特定问题。
- 可用工具: 它可以调用的所有函数或内置工具的定义(例如,check_inventory、send_email)。
- 结构化输出: 模型响应格式的定义,例如 JSON 对象。
为什么重要:从廉价演示到神奇产品
构建真正有效的人工智能智能体的秘诀与您编写的代码的复杂性关系不大,而与您提供的上下文的质量息息相关。
构建智能体与你编写的代码或使用的框架关系不大。廉价的演示版和“神奇”的智能体之间的区别在于你提供的上下文的质量。想象一下,一个人工智能助手被要求根据一封简单的电子邮件安排一次会议:
嘿,只是想看看你明天是否有空进行快速同步。
“廉价演示”智能体的上下文信息很差。它只看到用户的请求,其他什么都看不到。它的代码可能功能完美——调用 LLM 并得到响应——但输出却毫无帮助,而且机械化:
谢谢你的留言。我明天有空。请问你打算几点?
神奇 "的智能体由丰富的上下文驱动。代码的主要工作并不是找出如何响应,而是收集 LLM 所需的信息,以全面实现其目标。在调用 LLM 之前,您可以扩展上下文,使其包括
- 您的日历信息(显示您的日程已满)。
- 您过去与此人的电子邮件往来(以确定适当的非正式语气)。
- 您的联系人列表(以将他们标识为关键合作伙伴)。
- send_invite 或 send_email 的工具。
然后你就可以生成响应。
嘿,吉姆!明天我这边会很忙,一整天都在忙。周四上午你方便吗?已经发邀请了,方便的话告诉我一声。
从提示到情境工程
什么是上下文工程?“提示工程”侧重于在单个文本字符串中编写完美的指令集,而上下文工程的范围则要广泛得多。简单来说:
上下文工程是:
- 系统,而非字符串:上下文不仅仅是一个静态的提示模板。它是在主 LLM 调用之前运行的系统的输出。
- 动态: 动态创建,根据当前任务量身定制。对于一个请求,这可能是日历数据,而对于另一个请求,可能是电子邮件或网页搜索。
- 关于在正确的时间提供正确的信息和工具: 核心工作是确保模型不遗漏关键细节(“垃圾进,垃圾出”)。这意味着仅在需要且有用时才提供知识(信息)和能力(工具)。
- 格式至关重要: 信息呈现方式至关重要。简洁的摘要胜过原始数据转储。清晰的工具架构胜过模糊的说明。
结论
构建强大可靠的 AI 智能体不再仅仅需要找到神奇的提示或模型更新,而是需要设计情境,并在正确的时间以正确的格式提供正确的信息和工具。这是一个跨职能的挑战,需要理解业务用例、定义输出,并构建所有必要信息,以便 LLM 能够“完成任务”。
本文转载自: https://www.philschmid.de/context-engineering