

DeepSeek-R1-Zero的复现调试(swanlab观测实验过程)

kyle
基于Qwen模型在SwanLab上复现DeepSeek-R1-Zero
简介
本文旨在对deepseek-r1-zero进行复现实验,详细介绍了从r1原理到代码实现,再到结果观测的整个过程。在实验中,采用了基石智算平台来实现GRPO(基于PPO的优化算法),并通过SwanLab监控实验过程,确保实验的每个阶段都能精确跟踪与调试。通过这一系列的实验步骤,本文希望帮助用户更好地理解基石智算平台的使用方式,并深入掌握GRPO的实现方法。希望读者在实验过程中能够加深对相关技术的理解,并能灵活应用于实际项目中。

DeepSeek-R1原理
论文标题:DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
论文链接:论文链接
代码地址:github链接
下面是论文里从DeepSeek-V3到DeepSeek-R1的流程图表示
本文仅考虑从DeepSeek-V3—>DeepSeek-R1-Zero的复现过程,基于Qwen2.5-7B-Instruct模型实现。因此下面仅介绍R1-Zero的复现过程。
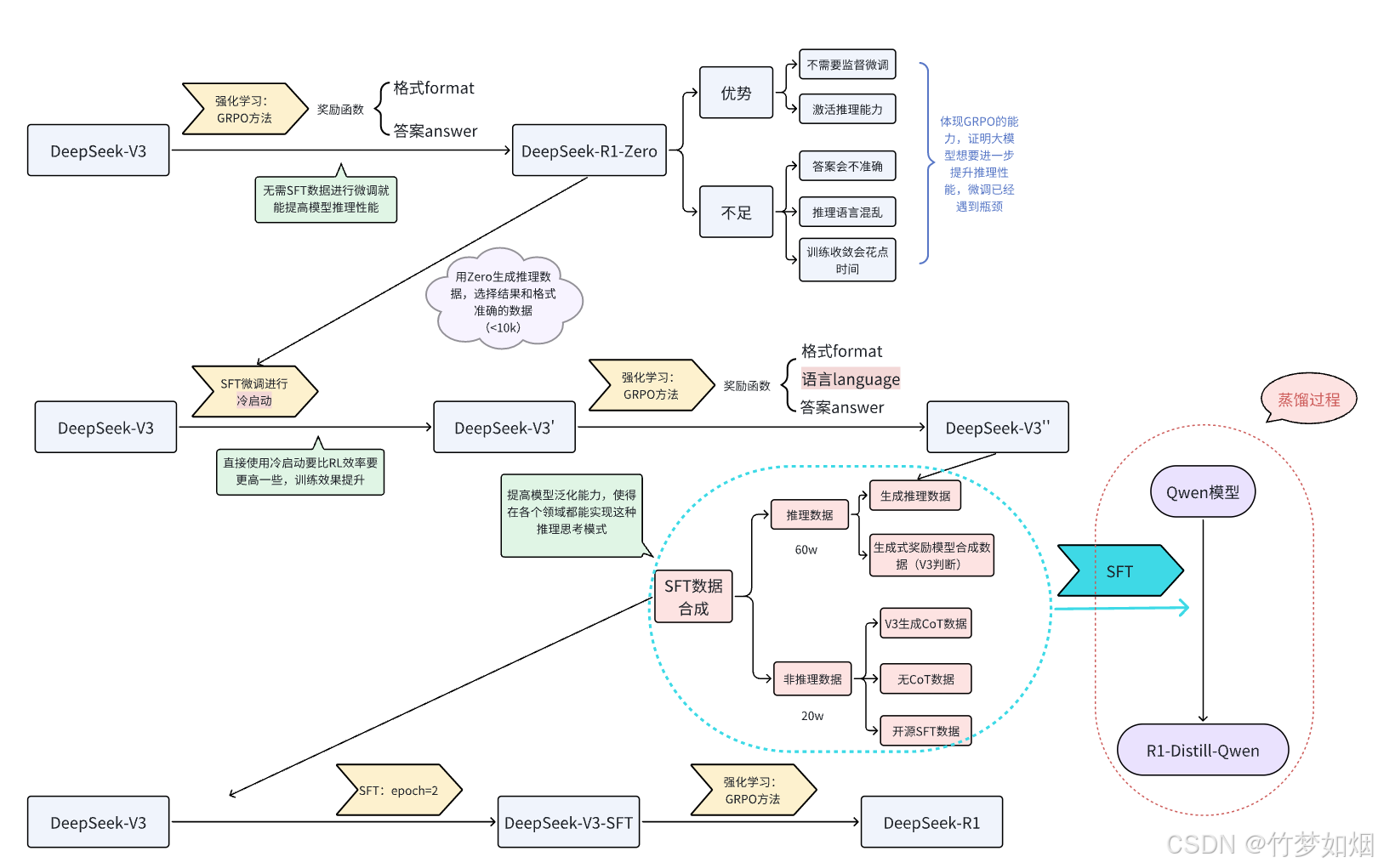
若希望激活较小规模的大语言模型的推理能力,使其具备类似R1的推理思考能力,DeepSeek官方已提供了一种高效的解决方案——GRPO强化学习方法。该方法可参照流程图中第一行的步骤。
具体过程我们可以从图中看到,官方使用V3对格式(format)以及答案(answer)设置奖励函数进行强化训练,使用GRPO策略,该策略是PPO的优化方案,能够显著的减少显存占用,提高训练效率,训练完毕后的模型能够获得类似于zero的思考能力,显著提高了模型的性能,但是结果仍会有些错误,并且强化学习后的结果毕竟不如SFT(监督微调)的结果稳定,所以R1仍然需要一些SFT来提高模型稳定性。
GRPO原理:
群体相对策略优化 (GRPO,Group Relative Policy Optimization)是一种强化学习 (RL) 算法,专门用于增强大型语言模型 (LLM) 中的推理能力。与严重依赖外部评估模型(价值函数)指导学习的传统 RL 方法不同,GRPO 通过评估彼此相关的响应组来优化模型。这种方法可以提高训练效率,使 GRPO 成为需要复杂问题解决和长链思维的推理任务的理想选择。
GRPO 的本质思路:通过在同一个问题上生成多条回答,把它们彼此之间做“相对比较”,来代替传统 PPO 中的“价值模型”
传统的强化学习算法(如Proximal Policy Optimization,PPO)在应用于LLMs的推理任务时面临着重大挑战:
1、依赖批评者模型:
PPO需要一个独立的批评者模型来评估每个回答的价值,这使内存和计算需求增加了一倍。
训练批评者模型非常复杂且容易出错,尤其是在需要对主观或细微差别进行评价的任务中。
2、高昂的计算成本:
强化学习流程通常需要大量计算资源来迭代评估和优化回答。
将这些方法扩展到更大的LLMs会进一步加剧成本。
3、可扩展性问题:
绝对奖励评估难以应对多样化任务,使得跨推理领域的泛化变得困难。
GRPO如何应对这些挑战:
1、无批评者优化: GRPO通过比较组内回答,消除了对批评者模型的需求,显著降低了计算开销。
2、相对评估: GRPO不依赖外部评价者,而是利用组内动态来评估每个回答在同一批次中的相对表现。
3、高效训练: 通过专注于组内优势,GRPO简化了奖励估计流程,使其对大型模型的训练更快且更具可扩展性。
下图是PPO与GRPO的对比,GRPO放弃了价值模型,从分组得分中估计,显著减少了训练资源
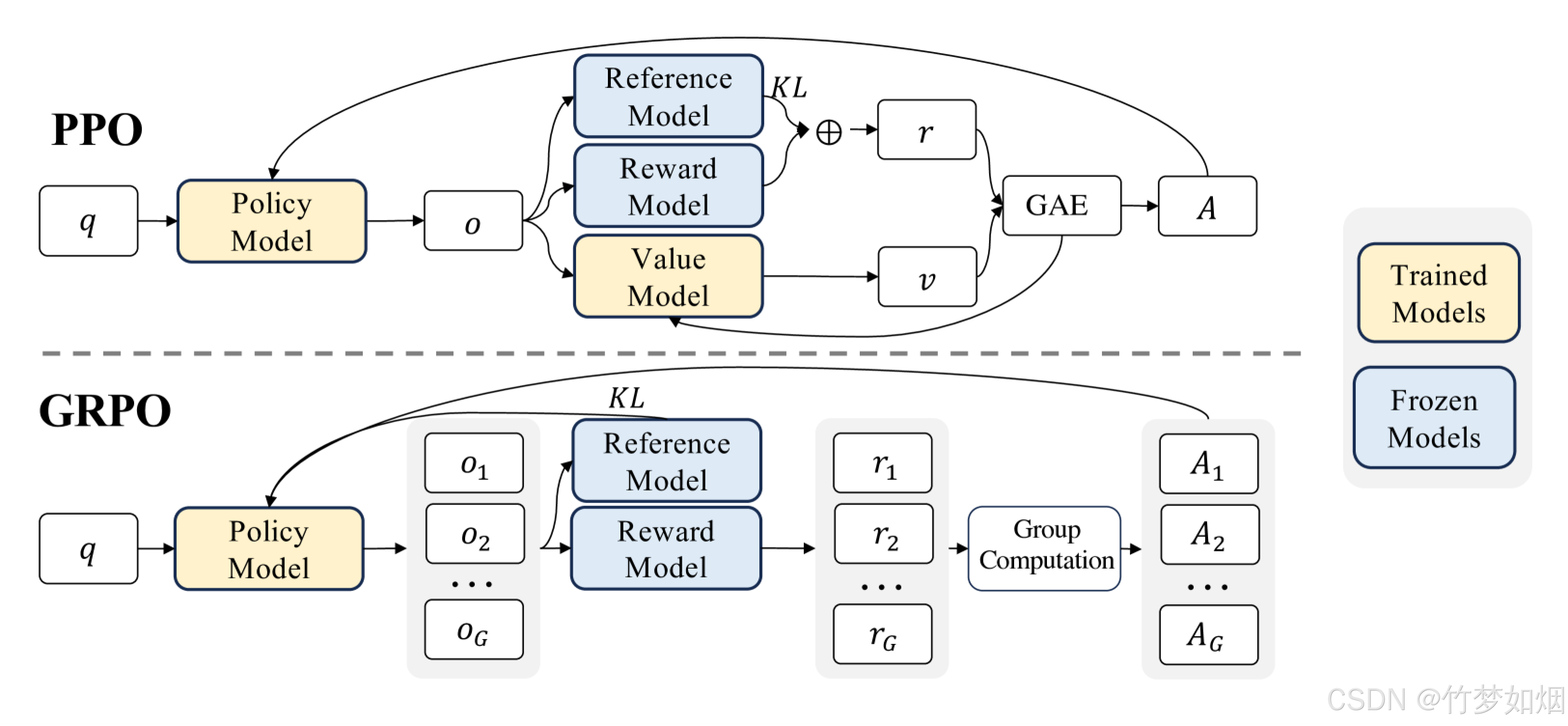
看到一位作者的看法,把GRPO比作老师给学生上课,老师让一组学生解决一个问题。
老师没有单独为每个学生打分,而是让学生在组内比较彼此的答案。表现更好的学生会得到鼓励,而其他人则从错误中学习。随着时间的推移,整个组会逐渐提高,变得更准确和一致。GRPO 将这一原理应用于训练AI模型,使其能够高效地学习。
实验工具选择

本次实验我们使用基石智算平台和SwanLab工具来进行实验,其中基石智算平台主要实现强化学习阶段,SwanLab工具主要实现模型训练过程的观测以及GPU情况监测。
基石智算是一个为各行业提供面向人工智能场景的资源与服务的平台。它提供GPU云服务、AI训练集群、并行文件存储、镜像仓库等AI专用服务,确保资源的高效利用和成本优化。基石智算还具备分布式调度与管理能力,能够自动分配和管理算力资源,大幅缩短任务执行时间,提高工作效率。此外,基石智算平台支持一键启动、一键部署以及在线微调,助力用户打造专属AI应用,加速AI应用落地,提升业务智能化水平。
SwanLab是一款开源、轻量级的AI实验跟踪工具,提供了一个跟踪、比较、和协作实验的平台,旨在加速AI研发团队的研发效率。它提供了友好的API和漂亮的界面,结合了超参数跟踪、指标记录、在线协作、实验链接分享、实时消息通知等功能,让您可以快速跟踪ML实验、可视化过程、分享给同伴。SwanLab还支持云端和离线使用,支持远程查看训练过程,比如可以在手机上看远程服务器上跑的训练。此外,SwanLab自动记录训练过程中的日志、硬件环境、Python库以及GPU、NPU等硬件信息。
链接资料
作者信息:情感机器实验室研究员-李馨雨 邮箱:wind.340171@gmail.com
模型地址:huggingface社区|魔搭社区
数据集地址:huggingface-MATH23K
可视化工具SwanLab项目地址:SwanLab结果可视化
友情链接
基石智算平台链接:AI计算平台(用于模型训练部署等任务):AI计算平台
大模型推理服务平台(调用模型API,该平台提供了DeepSeek-R1以及蒸馏版本的API,可以轻松实现R1的本地调用):大模型推理服务平台
SwanLab官方文档:用户指南,可以快速上手SwanLab: 快速开始 | SwanLab官方文档
应用案例:入门实验 | SwanLab官方文档
实验代码
1、环境搭建
由于本次实验使用青云的基石智算平台,因此环境的搭建需要按照步骤来进行,这样能够节省查阅文档学习的时间,轻松上手。
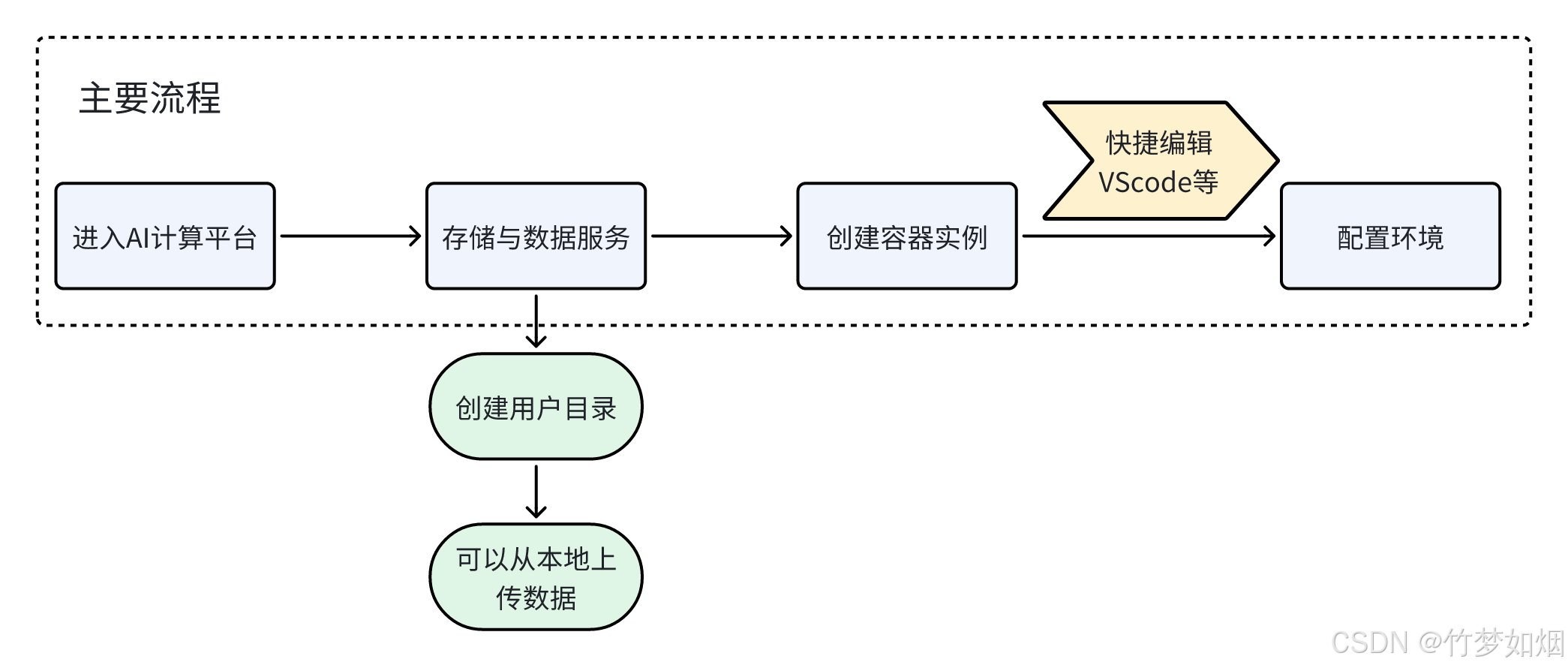
操作流程可以大致按照下面的流程图来进行,具体的步骤我会在下面详细介绍:

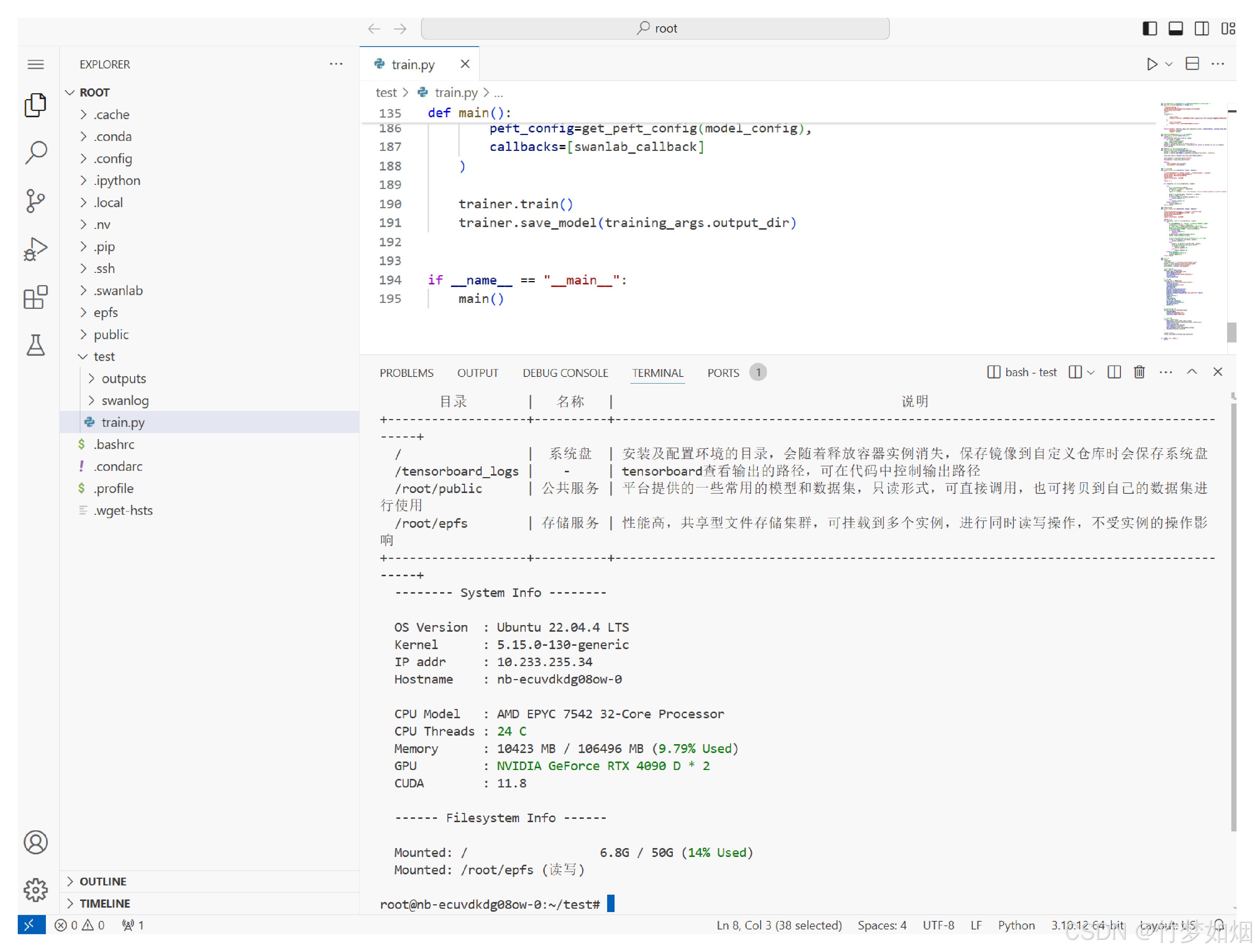
我们需要按照流程图中的主要流程来操作,而且最好是先设置存储与数据服务,此步骤是开启一个数据存放地址,可以在该文件夹中上传本地数据,而后续创建容器实例的时候会要求设置存储与数据服务,如果没有提前设置,那么申请下来的服务器就没有该地址,需要重新申请服务器来设置。
在存储与数据服务以及容器实例创建好后就可以直接在快捷IDE界面编辑训练代码并且训练。
step1:创建存储与数据服务
step2:创建容器实例

step3:配置环境
环境设置如下:
pip install transformers==4.48.1
pip install peft==0.14.0
由于我使用的是pytorch基础镜像,其中pytorch版本有点低,所以我重新安装了2.4.0版本的pytorch,需要注意:该服务器CUDA等配置可能不是很完整,因此为了节省时间,我们直接安装CPU版本,如果有条件可以安装支持CUDA的PyTorch版本。
pytorch安装地址:pytorch-old-versions
conda install pytorch2.4.0 torchvision0.19.0 torchaudio==2.4.0 -c pytorch
pip install datasets
pip install accelerate>\=0.26.0
pip install trl
pip install -U swanlab
2、数据预处理
本次实验使用一个23k条数据的数学问答数据集来进行实验,内容如下图所示:
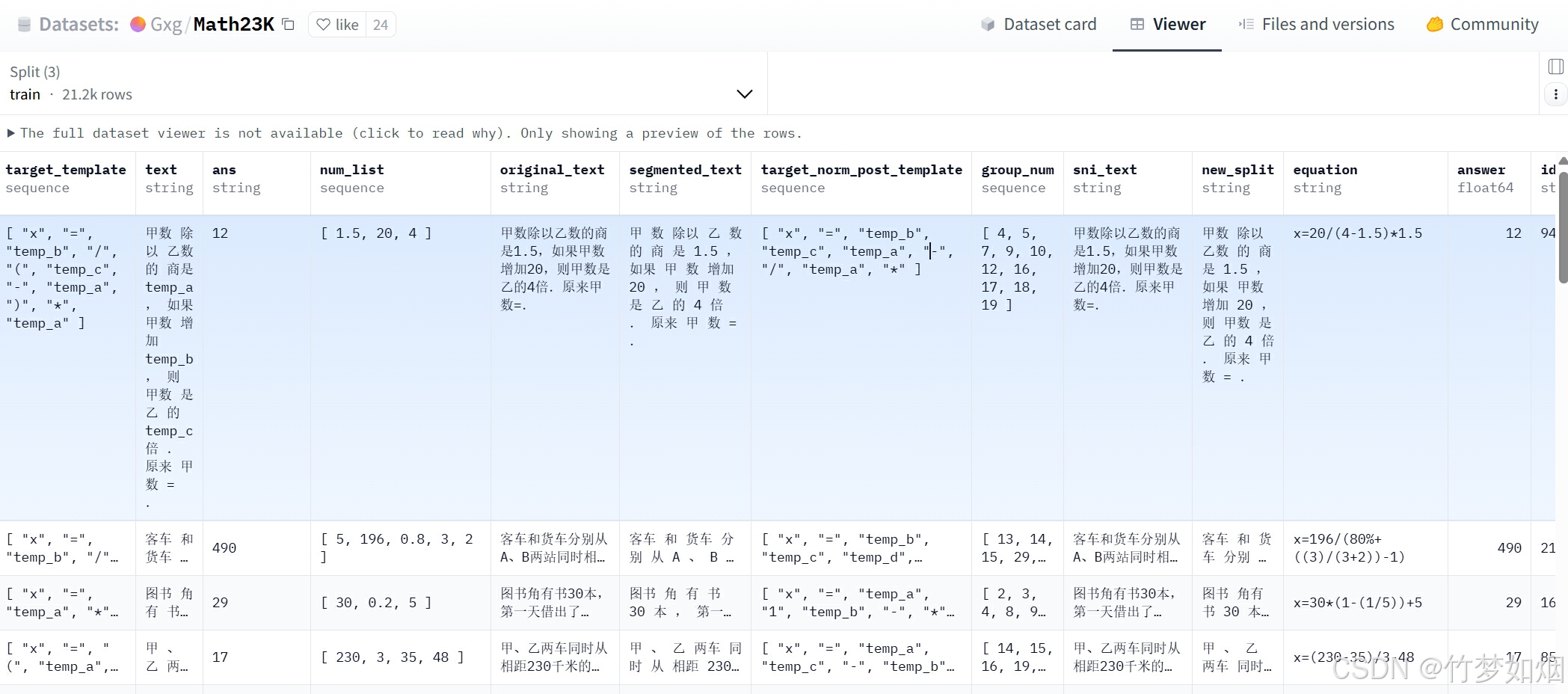
我们只需要其中sni_text以及ans,也就是问题和答案部分数据即可,因为强化训练需要让模型自己输出思考过程从而提高推理能力,而该数据集需要我们进行预处理,提取其中的问答对,并且需要设置prompt提示词令模型在训练过程中根据问题与答案生成思考过程。
提取两个字段后的数据如下,是jsonl格式保存:
{"sni_text": "甲数除以乙数的商是1.5,如果甲数增加20,则甲数是乙的4倍.原来甲数=.", "ans": "12"}
{"sni_text": "客车和货车分别从A、B两站同时相向开出,5小时后相遇.相遇后,两车仍按原速度前进,当它们相距196千米时,货车行了全程的80%,客车已行的路程与未行的路程比是3:2.求A、B两站间的路程.", "ans": "490"}
然后读取jsonl文件成Dataset格式用于方便处理数据
def read_jsonl_to_dataset(jsonl_file:str):
records = []
with jsonlines.open(jsonl_file) as reader:
for record in reader:
records.append(record)
# 假设所有记录都有相同的列名
columns = records[0].keys() if records else []
dataset = Dataset.from_dict({col: [record[col] for record in records] for col in columns})
return dataset
最重要的是将数据集转换为R1 Countdown提示词格式
```
模仿R1的prompt格式来处理数据集,使得GRPO的时候的数据集是可以有思考过程
def generate_r1_prompt(question:str,target:str): """ 激活qwen模型的思考过程 :param question:数据集的question,给qwen让他自己思考去 :param target:数据集的ans :return: """ r1_prefix = [ { "role":"user", "content":f"现在有一个数学问题,内容是:{question},答案是{target},你需要根据问题思考其推理过程,使得最终能够得到正确答案,在和标签中展示你的思考过程,并在和标签中返回最终答案,比如19。在标签后逐步思考。" }, { "role":"assistant", "content":"让我们逐步解决这个问题。\n" } ] # apply_chat_template是应用qwen模型文件中tokenizer_config.json文件中chat_template提示词模板来生成回答。 return {"prompt": tokenizer.apply_chat_template(r1_prefix, tokenize=False, continue_final_message=True), "question":question, "target": target}
将数据集转换为R1 Countdown提示词格式,在这里我们会把prompt转换为Qwen2的提示词模版,让它以更熟悉的方式来接收提示词,并且我们把让我们逐步解决这个问题。\n作为模型输出的开头,让它接着续写。用 Python字典的方式返回样本,这样trl会在调用奖励函数的时候,帮我们把键名设为为对应的参数;另外,trl会把模型的多个输出设为completions。
def train_dataset_process(train_data_path:str): dataset = read_jsonl_to_dataset(train_data_path) dataset = dataset.map(lambda x: generate_r1_prompt(x["sni_text"], x["ans"]))
train_test_split = dataset.train_test_split(test_size=0.1)
train_dataset = train_test_split["train"]
test_dataset = train_test_split["test"]
return {
"train_dataset":train_dataset,
"test_dataset":test_dataset
}
```
注意: generate_r1_prompt中最终需要return包含数据提问,以及数据集对应的答案answer,map方法会帮我们把实际的question和answer填入到prompt里
3、设置奖励函数
在强化学习中,奖励函数是指导智能体(agent)在环境中如何行动的核心信号。奖励提供了对智能体行为的即时反馈,用于评估某个动作在某一状态下的好坏,从而影响其未来的决策。通过不断地试错和调整,智能体学习到在不同状态下选择能获得高奖励的行为策略。奖励的主要功能是引导智能体朝着最大化长期回报的目标去优化策略。正向奖励(正数)鼓励行为,负向奖励(负数)抑制行为。奖励用于更新智能体的策略或值函数,策略的优化通常基于累计奖励(Return),即智能体从当前状态到未来一段时间内获得的总奖励。
本次实验我们仅对输出格式format以及最终答案answer设置奖励函数,训练过程会不断修正格式输出以及答案输出。
format奖励函数
```
格式奖励函数
def format_reward_func(completions, target, **kwargs): """ 格式奖励函数:要确保格式Format: ...... :param completions: Qwen模型生成的推理内容 :param target: 数据集ans对应的答案 :param kwargs: :return:list[float]: 奖励分数 """ rewards = []
for completion, gt in zip(completions, target):
try:
# 添加<think>以便后续正则化
completion = "<think>" + completion
# 检查格式是否正确
regex = r"^<think>([^<]*(?:<(?!/?think>)[^<]*)*)<\/think>\n<answer>([\s\S]*?)<\/answer>$"
match = re.search(regex, completion, re.DOTALL)
# 如果格式正确,奖励为1
if match is None or len(match.groups()) != 2:
rewards.append(0.0)
else:
rewards.append(1.0)
except Exception:
rewards.append(0.0)
return rewards
```
answer奖励函数
```
答案奖励函数
def answer_reward_func(completions, target, kwargs): """ 答案奖励函数,要确保...中间的答案是对的 :param completions:Qwen生成的回答,很长一段话 :param target:数据集的答案 :param kwargs: :return:list[float]: 奖励分数 """ rewards = [] for completion, goal in zip(completions, target): try: # 在Qwen生成的输出添加标签,以便后续正则表达式的匹配 completion = "" + completion # 检查输出的格式是否正确,判断是否在回答里 match = re.search(r"(.?)<\/answer>", completion) # 如果没有这样的标签的话,奖励分数是0 if match is None: rewards.append(0.0) continue # 得到后面的答案,判断是否准确 answer = match.group(1).strip() # 如果答案里有文字的话,奖励为0,如果不是,进行后续判断 if not re.fullmatch(r'\d+\s\d', answer): rewards.append(0.0) else: answer = re.match(r'^\s(\d+)\s*$', answer) # 如果正确,就是1分,如果不对,直接0分 if answer == goal: rewards.append(1.0) else: rewards.append(0.0) except Exception: # 如果评估失败,则奖励为0 rewards.append(0.0) return rewards ```
补充: 也可以设置思考长度以及语言一致性奖励函数来提高模型性能
4、设置模型参数
```
模型参数设置
model_config = ModelConfig( model_name_or_path=model_path, torch_dtype="bfloat16", attn_implementation="flash_attention_2", use_peft=True, load_in_4bit=True ) ```
5、设置训练参数
```
训练参数
training_args = GRPOConfig( output_dir="/root/test/outputs/math23k", learning_rate=5e-7, lr_scheduler_type="cosine", logging_steps=2, max_steps=200, per_device_train_batch_size=1, gradient_checkpointing=True, gradient_accumulation_steps=8, gradient_checkpointing_kwargs={"use_reentrant": False}, bf16=True, save_steps=50, # GRPO参数设置 max_prompt_length=256, max_completion_length=1024, num_generations=2, beta=0.001, ) ```
6、设置SwanLab可视化训练工具参数
SwanLab是一款完全开源免费的机器学习日志跟踪与实验管理工具,为人工智能研究者打造。有以下特点:
1、基于一个名为swanlab的python库
2、可以帮助您在机器学习实验中记录超参数、训练日志和可视化结果
3、能够自动记录logging、系统硬件、环境配置(如用了什么型号的显卡、Python版本是多少等等)
4、同时可以完全离线运行,在完全内网环境下也可使用
如果想要快速入门,请参考以下文档链接:
用户指南,可以快速上手SwanLab: 快速开始 | SwanLab官方文档
应用案例:入门实验 | SwanLab官方文档
代码设置如下:
```
swanlab参数配置
swanlab_callback = SwanLabCallback( workspace=None, # 项目不公开 project="DeepSeek-R1-zero", # 项目名称 experiment_name="4090-grpo", # 实验名称 ) ```
7、训练并保存模型
```
训练器配置
trainer = GRPOTrainer( model=model_config.model_name_or_path, reward_funcs=[format_reward_func,answer_reward_func], args=training_args, train_dataset=train_dataset, eval_dataset=test_dataset, peft_config=get_peft_config(model_config), callbacks=[swanlab_callback] )
trainer.train() trainer.save_model(training_args.output_dir) ```
全过程代码
``` from transformers import AutoTokenizer,AutoModelForCausalLM import jsonlines from datasets import Dataset import re from swanlab.integration.transformers import SwanLabCallback from trl import GRPOConfig, GRPOTrainer, get_peft_config, ModelConfig
model_path = "/root/public/Qwen2-0.5B-Instruct"
tokenizer = AutoTokenizer.from_pretrained(model_path)
模仿R1的prompt格式来处理数据集,使得GRPO的时候的数据集是可以有思考过程
def generate_r1_prompt(question:str,target:str): """ 激活qwen模型的思考过程 :param question:数据集的question,给qwen让他自己思考去 :param target:数据集的ans :return: """ r1_prefix = [ { "role":"user", "content":f"现在有一个数学问题,内容是:{question},你需要根据问题思考其推理过程,使得最终能够得到正确答案,在和标签中展示你的思考过程,并在和标签中仅返回最终答案,答案仅包含数字答案,无其他描述,比如19。在标签后逐步思考。" }, { "role":"assistant", "content":"让我们逐步解决这个问题。\n" } ]
return {"prompt": tokenizer.apply_chat_template(r1_prefix, tokenize=False, continue_final_message=True),
"question":question,
"target":target}
读取jsonl文件成Dataset格式用于方便处理数据
def read_jsonl_to_dataset(jsonl_file:str): records = [] with jsonlines.open(jsonl_file) as reader: for record in reader: records.append(record) # 假设所有记录都有相同的列名 columns = records[0].keys() if records else [] dataset = Dataset.from_dict({col: [record[col] for record in records] for col in columns}) return dataset
将数据集转换为R1 Countdown提示词格式
def train_dataset_process(train_data_path:str): dataset = read_jsonl_to_dataset(train_data_path) dataset = dataset.map(lambda x: generate_r1_prompt(x["sni_text"], x["ans"]))
train_test_split = dataset.train_test_split(test_size=0.1)
train_dataset = train_test_split["train"]
test_dataset = train_test_split["test"]
return {
"train_dataset":train_dataset,
"test_dataset":test_dataset
}
格式奖励函数
def format_reward_func(completions, target, **kwargs): """ 格式奖励函数:要确保格式Format: ...... :param completions: Qwen模型生成的推理内容 :param target: 数据集ans对应的答案 :param kwargs: :return:list[float]: 奖励分数 """ rewards = []
for completion, gt in zip(completions, target):
try:
# 添加<think>以便后续正则化
completion = "<think>" + completion
# 创建生成输出目录(如果不存在)
os.makerdirs("completion_samples",exist_ok=True)
log_file = os.path.join("completion_samples","completion_samples.txt")
with open(log_file,"a") as f:
f.write(f"\n\n======================\n")
f.write(completion)
# 检查格式是否正确
regex = r"^<think>([^<]*(?:<(?!/?think>)[^<]*)*)<\/think>\n<answer>([\s\S]*?)<\/answer>$"
match = re.search(regex, completion, re.DOTALL)
# 如果格式正确,奖励为1
if match is None or len(match.groups()) != 2:
rewards.append(0.0)
else:
rewards.append(1.0)
except Exception:
rewards.append(0.0)
return rewards
答案奖励函数
def answer_reward_func(completions, target, *kwargs): """ 答案奖励函数,要确保...中间的答案是对的 :param completions:Qwen生成的回答,很长一段话 :param target:数据集的答案 :param kwargs: :return:list[float]: 奖励分数 """ rewards = [] for completion, goal in zip(completions, target): try: # 在Qwen生成的输出添加标签,以便后续正则表达式的匹配 completion = "" + completion # 检查输出的格式是否正确,判断是否在回答里 match = re.search(r"(.?)<\/answer>", completion) # 如果没有这样的标签的话,奖励分数是0 if match is None: rewards.append(0.0) continue # 得到后面的答案,判断是否准确 answer = match.group(1).strip()
# 创建生成输出目录(如果不存在)
os.makerdirs("completion_samples",exist_ok=True)
log_file = os.path.join("completion_samples","answer_samples.txt")
with open(log_file,"a") as f:
f.write(f"\n\n======================\n")
f.write(completion)
# 如果答案里有文字的话,奖励为0,如果不是,进行后续判断
if not re.fullmatch(r'\d+\s*\d*', answer):
rewards.append(0.0)
else:
answer = re.match(r'^\s*(\d+)\s*$', answer)
# 如果正确,就是1分,如果不对,直接0分
if answer == goal:
rewards.append(1.0)
else:
rewards.append(0.0)
except Exception:
# 如果评估失败,则奖励为0
rewards.append(0.0)
return rewards
训练过程
def main(): # 数据处理 train_data_path = "/root/epfs/train_math23k.jsonl" dataset = train_dataset_process(train_data_path) train_dataset = dataset['train_dataset'] test_dataset = dataset['test_dataset']
# 模型参数设置
model_config = ModelConfig(
model_name_or_path=model_path,
torch_dtype="bfloat16",
attn_implementation="flash_attention_2",
use_peft=True,
load_in_4bit=True
)
# 训练参数
training_args = GRPOConfig(
output_dir="/root/test/outputs/math23k",
learning_rate=5e-7,
lr_scheduler_type="cosine",
logging_steps=2,
max_steps=200,
per_device_train_batch_size=1,
gradient_checkpointing=True,
gradient_accumulation_steps=8,
gradient_checkpointing_kwargs={"use_reentrant": False},
bf16=True,
save_steps=50,
# GRPO参数设置
max_prompt_length=256,
max_completion_length=1024,
num_generations=2,
beta=0.001,
)
## swanlab参数配置
swanlab_callback = SwanLabCallback(
workspace=None,
project="DeepSeek-R1-zero",
experiment_name="4090-grpo",
)
# 训练器配置
trainer = GRPOTrainer(
model=model_config.model_name_or_path,
reward_funcs=[format_reward_func,answer_reward_func],
args=training_args,
train_dataset=train_dataset,
eval_dataset=test_dataset,
peft_config=get_peft_config(model_config),
callbacks=[swanlab_callback]
)
trainer.train()
trainer.save_model(training_args.output_dir)
if name == "main": main() ```
基石智算平台使用细节
1、创建容器实例后关机会自动在自定义镜像仓库生成自定义镜像
2、可以调用API实现大模型本地使用
实验结果演示
首先我们可以在基石智算平台中直接监控GPU情况:
而更多的细节我们可以使用swanlab工具来观测,既可以看到模型训练的时候loss、reward分数、lr等参数的变化,也可以直接查看GPU、NPU等加速卡的情况:
由于时间step比较少,而且本次实验选择0.5B的模型比较小,所以短时间内效果并不明显,也许更换更大的模型能够实现GRPO的"顿悟时刻"
✨✨✨至此,您已完成全部的教程✨✨✨
---
文章来源:https://blog.csdn.net/weixin_44312617/article/details/145603270