


Linux GPU环境下 DeepSeek-R1 模型一键式安装与运行脚本说明

ghostblue
2025-02-13 发布1178 浏览 · 1 点赞 · 1 收藏
本文档是关于在Linux服务器上使用Shell脚本一键式安装和运行DeepSeek-R1大语言模型环境的详细说明。
环境要求
在运行脚本之前,请确保以下条件满足:
- 操作系统:Linux
- 硬件:配备NVIDIA GPU的服务器
- 软件:
- CUDA版本:12.4或更高版本
- Docker:已安装并配置好,当前用户有docker执行权限。
- NVIDIA Container Toolkit:已安装并配置好(以支持Docker GPU加速)
- 环境已安装Git
- 用户要求:有一定Linux操作基础。
- 如不满足上述条件,可参考另行推出的Windows下的DeepSeek-R1安装指南。
最简安装过程
1. 克隆仓库或获取脚本
将脚本文件 (ubuntu/cuda_ollama_openwebui.sh) 下载到服务器上,例如通过以下命令:
git clone git@atomgit.com:awesome-deepseek/deeponeclick.git
2. 运行脚本
bash deeponeclick/ubuntu/cuda_ollama_openwebui.sh
如何无特殊配置需求,一路回车,跳过所有交互,直到屏幕输出:“Ollama和openWebUI已启动,访问http://服务器IP:${user_port}” 即可。
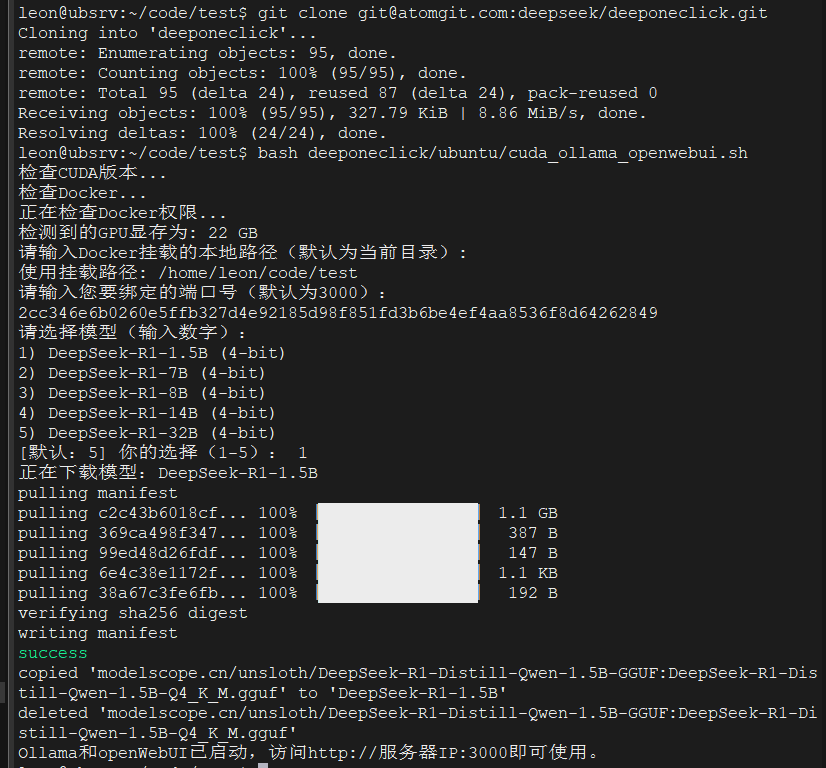
3. 体验模型
- 根据脚本提示,打开浏览器访问上述地址:
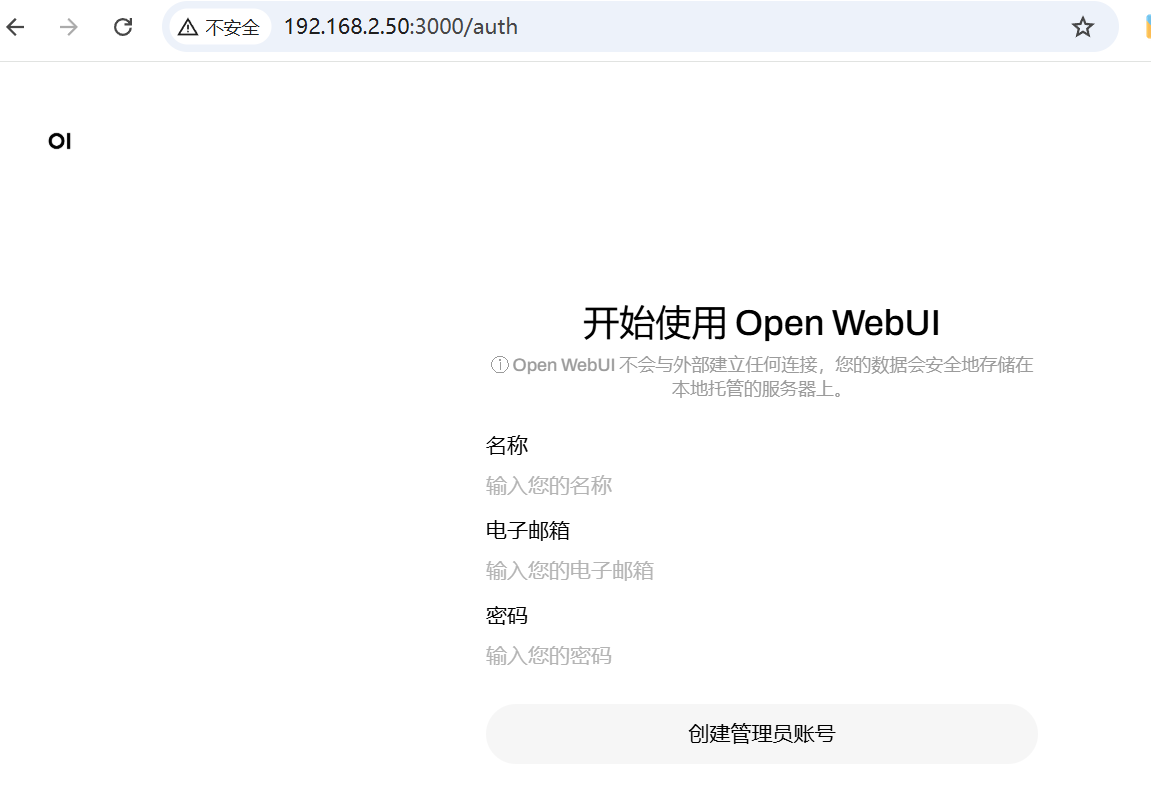
- 按提示注册用户后即可愉快的使用DeepSeek-R1模型聊天:

- 例如,你可以如下问DeepSeek,看有什么惊喜:
写一个shell脚本,实现在一个ubuntu 服务器且安装有gpu和docker的服务器上安装运行一个ghcr.io/open-webui/open-webui:ollama 容器。要求实现以下功能
1. 使用cuda_version=$(nvidia-smi | grep -oP 'CUDA Version: \K[0-9.]+')检查服务器是否安装了cuda,cuda版本是否在12.4以上,不是给出错误退出。
2. 检查是否安装了docker,没安装则退出
3. 获取gpu的显存多少GB,可以用nvidia-smi --query-gpu=memory.total --format=csv,noheader,nounits | awk '{print $1}' 获取显存的MB数
4. 让用户输入docker挂载的本地路径,默认为当前路径
5. 使用docker run -d -p 3000:8080 --gpus=all -v 挂载路径/ollama:/root/.ollama -v 挂载路径/open-webui:/app/backend/data --name open-webui --restart always ghcr.nju.edu.cn/open-webui/open-webui:ollama 运行容器
脚本功能
该脚本的主要功能如下:
-
系统检查:
- 检查CUDA版本是否为12.4或更高。
- 确保Docker已安装,确保当前用户有docker权限。
-
用户输入:
- 提供默认值的挂载路径(默认为当前目录)。
- 提供默认值的端口号(默认为3000)。
-
容器运行:
- 使用指定的端口号和挂载路径启动集成Ollama的openWebUI容器。
- 挂载本地目录到容器内:
{挂载路径}/ollama映射到容器的/root/.ollama{挂载路径}/open-webui映射到容器的/app/backend/data
- 配置容器始终重启策略。
-
下载DeepSeek-R1模型:
- 支持以下模型可供选择。为减少国内用户等待时间,模型将从魔搭社区下载。
| 序号 | 模型名称 | 参数量 | 显存 | 实际下载地址 |
|---|---|---|---|---|
| 1 | deepseek-r1:1.5b | 1.5B | < 1GB | modelscope.cn/unsloth/DeepSeek-R1-Distill-Qwen-1.5B-GGUF:DeepSeek-R1-Distill-Qwen-1.5B-Q4_K_M.gguf |
| 2 | deepseek-r1:7b | 7B | < 5 GB | modelscope.cn/unsloth/DeepSeek-R1-Distill-Qwen-7B-GGUF:DeepSeek-R1-Distill-Qwen-7B-Q4_K_M.gguf |
| 3 | deepseek-r1:8b | 8B | < 6 GB | modelscope.cn/unsloth/DeepSeek-R1-Distill-Llama-8B-GGUF:DeepSeek-R1-Distill-Llama-8B-Q4_K_M.gguf |
| 4 | deepseek-r1:14b | 14B | < 10 GB | modelscope.cn/unsloth/DeepSeek-R1-Distill-Qwen-14B-GGUF:DeepSeek-R1-Distill-Qwen-14B-Q4_K_M.gguf |
| 5 | deepseek-r1:32b | 32B | < 20 GB | modelscope.cn/unsloth/DeepSeek-R1-Distill-Qwen-32B-GGUF:DeepSeek-R1-Distill-Qwen-32B-Q4_K_M.gguf |
- 根据环境显卡显存大小提供默认最佳尺寸的模型版本。
- 用户可根据需要自行选择。
脚本交互说明
脚本运行时会提示用户输入以下信息:
-
挂载路径:
- 默认值:当前目录(
$PWD) - 格式:
请输入Docker挂载的本地路径(默认为当前路径,即$PWD):
如果用户不输入任何内容并按回车,脚本会使用当前目录作为挂载路径。
- 默认值:当前目录(
-
绑定的端口号:
- 默认值:
3000 - 格式:
请输入您要绑定的端口号(默认为3000):
如果用户不输入任何内容并按回车,脚本会使用默认值。
- 默认值:
-
选择模型:
- 默认值:
- 如果GPU显存在18GB以上,则默认5: deepseek-r1:32b
- 如果GPU显存在12GB以上,则默认4: deepseek-r1:14b
- 如果GPU显存在6GB以上,则默认3: deepseek-r1:8b
- 如果GPU显存在6GB以下,则默认1: deepseek-r1:1.5b
- 格式:
[默认:5] 你的选择(1-5):
如果用户不输入任何内容并按回车,脚本会使用默认值。
- 默认值:
常见问题解答
1. Docker未安装
- 解决方法:使用下面命令安装Docker并确保其运行。
sudo -i
bash <(curl -sSL https://linuxmirrors.cn/docker.sh)
2. 当前用户无docker运行权限
- 解决方法:给当前用户docker运行权限。
sudo usermod -aG docker $USER
3. 端口号已被占用
- 解决方法:更换一个未被占用的端口号。
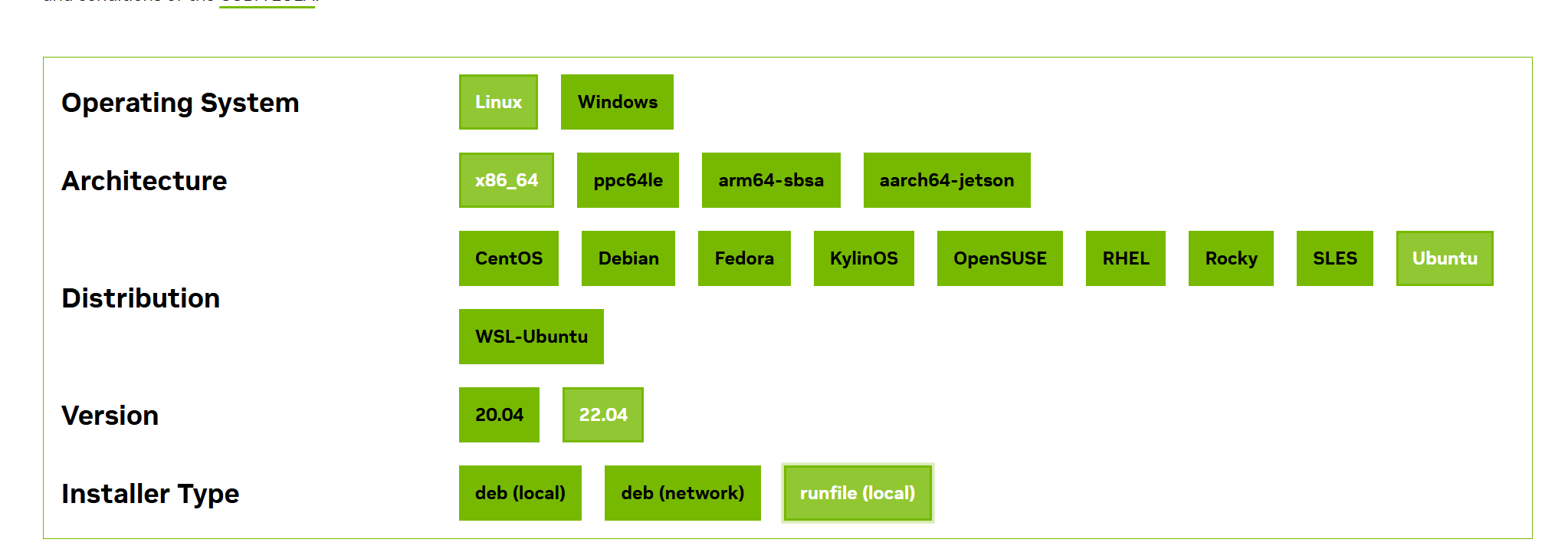
4. CUDA未安装或版本不满足要求
- 解决方法:访问https://developer.nvidia.com/cuda-toolkit-archive。选择新的CUDA版本,按提示下载安装:
故障排除
如果在运行过程中遇到问题,可以尝试以下步骤:
-
检查容器日志:
docker logs open-webui -
重启容器:
docker restart open-webui -
停止并删除容器(如有必要):
docker rm -f open-webui sudo rm -rf {挂载路径}/ollama sudo rm -rf {挂载路径}/open-webui -
检查依赖项是否安装:
- 确保NVIDIA驱动、CUDA、Docker和NVIDIA Container Toolkit已正确安装。
支持
如果您在使用脚本时遇到问题,请通过以下方式获取帮助:
- 查看脚本日志。
- 检查Docker容器状态。
- 参考Open Web UI官方文档。
- 参考Ollama官方文档。
希望本文档能帮助您顺利部署DeepSeek-R1大模型!
请前往 登录/注册 即可发表您的看法…